Voice recognition research and trend analysis
Hye Min Yun, Eun Jung Choi
Seoul Women’s University
621,
Hwarang-ro, Nowon-gu, Seoul, Republic of Korea
Seoul, Republic of Korea
hyemin3307@naver.com, chej@swu.ac.kr
Abstract
Over the past several years, technologies such as cloud computing, machine learning, and deep learning have evolved, and voice recognition technology is advancing faster than in the past.
In addition, the use of virtual assistant using voice recognition is increasing, and natural speech processing technology, which is the basis of virtual assistant service, is also expanding.
In this paper, we will discuss the technical principle of voice recognition, the voice recognition technology used in the past, the artificial intelligence assistant service available in cell phones and speakers, and finally how voice recognition should be used in the future.
Keywords-component; formatting; style; voice recognition, AI, assitant service
1. Introduction
Voice recognition is
the process by which a computer interprets a person's voice and converts it
into text data. In other words, it is also called Speech-to-Text (STT). It is
used when you need to control the device or search for information by using
robot or telematics. A representative algorithm is HMM (Hidden Markov Model),
which constructs a speech model by statistically modeling voices spoken by
various speakers and constructs a language model by collecting as many people's
voices. It is also used for authentication such as identity verification
compared with the previously collected voice pattern, which is called speaker
recognition [1].
Voice recognition can be largely divided into a method of executing a
designated command using a mounted on a device and an method using a server. When
mounted on a device, it is based on a limited set of commands and can be called
quickly because it does not need to communicate with the server, but the range
of languages that can be loaded and natural conversations are limited. Server-based
execution has the disadvantage that it is not executed when the server is
disconnected, but it has the advantage of constantly updating and improving the
language and vocabulary used. In addition, search and service connection using
the Internet network is easy, and the possibility of expansion is unlimited.
Voice recognition is used as voice secretary using voice recognition as artificial intelligence develops. Now, functions such as daily conversation and emotional exchange are expanding. This makes it easy to use voice recognition in everyday mobile phones and IoT devices, and it has become a necessary function for many people. In addition, voice recognition is recognized as a next-generation authentication service because it can be remotely authenticated unlike other body authentication methods such as fingerprint and iris.
2. Voice Recognition
2.1. Principles of voice recognition technology
Voice recognition technology can be divided into voice recognition and speaker recognition. Voice recognition is categorized as a speaker dependent technology that recognizes specific speakers and speaker independent technologies that are recognized irrespective of speakers. The speaker dependent technology pre-stores and registers the user's voice and compares and recognizes the pattern of the stored voice and the pattern of the voice inputted when performing the actual recognition and is excellent in recognition performance. Speaker independent technology targets unspecified speakers, so it is necessary to have a large amount of speech database to improve accuracy when performing recognition.
Most voice recognition technologies have the following structure as shown in Fig. 1 and only speaker's speech feature is extracted from the input signal. Based on this, the pattern is classified by measuring the similarity with the existing speech model and processed as a human language based on the language model and recognized as a sentence.
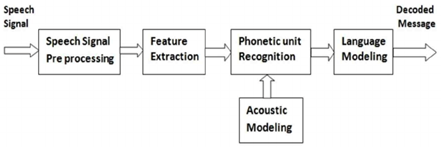
Fig.1[2]
In this case, even if a good recognition algorithm is used, it is difficult to expect a high recognition rate unless the detection is performed properly. Therefore, detecting the human voice greatly affects the performance of the recognition technology.
After the speech is detected, the feature of the speech is extracted. It is important to extract the features that can express the characteristics of the voice because the voice changes in various ways depending on the speaker's gender and age, and the sound changes when it is singled and when pronounced in words or sentences [3].
2.2. Past voice recognition technology [3]
In the 1950s, Bell Labs acoustical physicists in the United States developed an auditory system that recognizes people's numbers as a single voice. The combination of dozens of expressions based on the fact that the specific Hz region of the sound 'ah' is strong is able to synthesize sounds close to the human voice, so that the human voice can be described very concisely. When the mathematical model is coded to express the voice, it is possible to encode the voice. The rest of the researchers thought that applying the input voice to this model would detect the approximate pattern and the voice recognition would be completed.
In 1963, IBM unveiled a voice recognition device called the Schubbox at the World Fair., which allows the recognition of 16 spoken English words and even simple numeric calculations. However, because the tone of a person keeps changing, a prerequisite is that you must speak clearly in a quiet place. In other words, this mathematical model could not express well the 'articulation combination' in which the vowel is more or less the same as that of the preceding vowel in the words of more than two syllables.
Since then, IBM has solved the problems of HMM that Carnegie Mellon University applied to voice recognition, which was originally developed by voice recognition. The difference between 'ah' sounds is collected from a typical 'ah' to a high 'ah', and statistical learning is done on how 'ah' differs from the average 'ah'. In other words, it is a concept of the hidden Markov model to raise the recognition rate in a situation where there are various and uncertainties due to the limit of the data amount as if it cannot be expressed in a quiet place or cannot express the articulation combination well. Hidden Markov models (HMM) can represent speech statistically including time variations.
2.3. Voice recognition AI assistant service
Voice recognition AI secretary is literally a service that artificial intelligence acts as a secretary of the individual. Artificial intelligence, instead of people, is automated to help you get things done faster and provide convenience services to improve your quality of life. Google's assistant has changed to a feature that allows users to respond more frequently to requests and questions that are more accurate and results in more accurate responses, and the ability of existing search features to provide links to answers more directly. It also provides customization options for each user. This is possible because Google has been collecting most of the information about users from the past, such as home, anniversary, and schedule. For example, it is possible to acquire information in advance based on questions that have been asked in the past when asked about the route that is the closest to the house at the time of the closing hour [4]. Samsung's Bixbee is a new intelligent interface designed to accept information in a variety of input formats, including voice, text, and images, and to use smartphones intuitively and efficiently. It consists of four functions: voice, vision, reminder, and home. We enhanced personalization and expanded support services such as knowledge search and music recommendation playback. We have strengthened the search function of life information and general knowledge in connection with portal such as Naver, and utilized 'Samsung Pay', which is connected with banks, as a financial service platform such as remittance, exchange, and balance inquiry [5].
3. Conclusion[6]
The first voice recognition system in the '50s was able to recognize numbers only. Research institutes located in USA, Japan, UK, Soviet Union developed special hardware to recognize human voice and extended voice recognition technology to support 4 vowels and 9 consonants.
The Department of Defense's DARPA Speech Understanding Research Program from 1971 to 1976 is one of the largest projects and has been the basis for Carnegie Mellon's harpy speech understanding system. Harpy could understand 1,011 words, which is equivalent to the vocabulary level of a 3-year-old infant. In addition, Threshold Technology, the first voice recognition business, was established and voice recognition technology such as a system that can interpret various people's voice introduced by Bell Labs has developed rapidly.
In the '80s, we studied a new approach to analyzing what people were saying, and over a decade the perceptual vocabulary grew rapidly to thousands of words and had the potential to recognize unlimited vocabulary. One of the reasons was a new statistical method known as the Hidden Markov Model (HMM). The Kurzweil Text-to-Speech program in 1985 recognized 1,000 words and supported 5,000 words, and IBM's system had a similar function, but only by word-by-word recognition.
In the ‘90s, automatic speech technology developed rapidly, computers were equipped with faster processors, and the public could access voice recognition software.
Until 2001, the accuracy of voice recognition technology was 80%, which was stagnated for 10 years. Recognition systems have been able to perform well when language experience is limited, but they have still guessed sounds based on statistical models and the language experience has grown as the Internet has developed. Since then, Google Voice search for iPhone has emerged and Google has begun to develop again, providing the ability to do big data analysis needed to analyze the words and voice samples collected by the device. Since then, Google has developed more accurate and efficient ways of adding personalized perceptions.
It combines artificial intelligence with voice recognition and is developing radically and is being used by many people conveniently. With this feature, users will not only be able to control or text their mobile devices with voice, but will also be able to use various languages and voices. Future upgrades will be more sophisticated and more accurate, and people will become accustomed to talking to speakers, cell phones, and so on, as well as other devices.
Acknowledgment
This research was supported by the MISP (Ministry of Science, ICT & Future Planning), Korea, under the National program for Excellence in SW (2016-0-00022) supervised by the IITP (Institute for Information & communications Technology Promotion)
References
[1] TechTarget, “Voice recognition”, https://searchcrm.techtarget.com/definition/voice-recognition, 20181013
[2] ResearchGate, “voice recognition block diagram”, https://www.researchgate.net/figure/Basic-block-diagram-of-a-speech-recognition-system_fig1_281670062, 20181013
[3] The Happy Scribe blog, “history of voice recognition". https://www.happyscribe.co/blog/history-voice-recognition/, 20181013
[4] Google blog, “google assistant”, https://www.blog.google/products/assistant/first-smart-displays-google-assistant-are-now-available-stores/, 20181013
[5] Artificial intelligence platform technology market trend report, S&T Market Report vol.57, 2018.3, Science and Technology Promotion Agency (Korea)
[6] TOTAL VOICE TECHNOLOGIES, “timeline of voice recognition”, https://www.totalvoicetech.com/a-brief-history-of-voice-recognition-technology/, 20181013